Appearance
工作流批量新增缓慢优化技巧(API 批量操作)
场景:批量新增多条数据时执行缓慢、耗时不稳定,容易触发超时。
背景与目标
- 问题表现:批量新增 N 条数据耗时过长,工作流节点执行到后半段经常超时排队
- 优化目标:把“逐条新增”改为“分批新增”,并减少不必要的数据读取与循环
常见原因
- 循环内重复获取数据(同一份数据被多次查询/计算)
- 循环嵌套导致调用次数呈倍数增长
- 单条写入/单条接口调用次数过多,累计耗时叠加
- 一次性取数过大(过滤条件不精确)导致后续处理慢
优化要点(先做结构优化,再做批量写入)
- 减少重复获取数据的节点
- 减少循环嵌套
- 用 API 根据过滤条件获取新增时所需的数据(根据实际场景调整过滤条件,避免获取过多数据)
- 新增数据时,用 API 批量写入数据(根据性能和数据量调整批量大小)
方案结构(建议这样分模块写)
1. 前置准备
- 目标工作表(worksheetId)、应用(appId)
- 过滤条件(只取本次需要处理的数据)
- 批量大小(例如每批 50/100/200,按实际压测调整)
2. 明道云工作流配置(关键节点)
- 取数节点:只取一次、取精确、结果复用
- 代码块节点:把多条数据组装为批量请求
- 写入节点:调用批量新增接口(分批提交)
3. 代码块示例(推荐模板:筛选取数 + 分批新增)
完整模板代码放在同目录:code.js
3.1 你只需要改哪些地方(标红必改)
必改(复制模板后先改这里)
- 代码块入参:
input.appKey - 代码块入参:
input.sign CONFIG.source.worksheetId(来源表)CONFIG.source.controls(来源表取哪些字段)CONFIG.source.filters(来源表过滤条件)CONFIG.target.worksheetId(目标表)CONFIG.fieldMap(字段映射)
3.2 可选优化项(按性能调)
CONFIG.api.pageSize:筛选取数分页大小(默认 200)CONFIG.api.addRowsBatchSize:每批新增条数(默认 800,超时就调小)CONFIG.target.triggerWorkflow:写入时是否触发目标表工作流(触发越多越慢)CONFIG.log.enabled:是否输出耗时日志
3.3 配置结构速览(对照 code.js)
javascript
const CONFIG = {
api: {
appKey: input.appKey, // <Badge type="danger" text="必改" />
sign: input.sign, // <Badge type="danger" text="必改" />
baseUrl: 'https://yz.yixingdf.com/api/v2/open/worksheet',
pageSize: 200,
addRowsBatchSize: 800,
},
source: {
worksheetId: '<来源表 worksheetId>', // <Badge type="danger" text="必改" />
controls: ['只放本次需要的字段'], // <Badge type="danger" text="必改" />
filters: [
{
values: [input.id],
},
], // <Badge type="danger" text="必改" />
},
target: {
worksheetId: '<目标表 worksheetId>', // <Badge type="danger" text="必改" />
returnRowIds: false,
triggerWorkflow: true,
},
fieldMap: {
fieldA: (row, ctx) => row.xxx,
fieldB: (row, ctx) => ctx.yyy,
}, // <Badge type="danger" text="必改" />
log: {
enabled: true,
label: '批量新增',
},
}3.4 执行流程(你要讲给同事听的那一句话版)
- 按
CONFIG.source一次性筛选取数 →CONFIG.fieldMap组装成新增 rows → 按CONFIG.api.addRowsBatchSize分批调用addRows写入CONFIG.target
Demo(按现有工作流拆解写法)
目标:给同事一份“照着现有工作流逐节点对照”的说明。你只要把每一步的截图/参数补上即可。
Demo 信息
- 工作流名称:审核
- 触发方式:手动触发
- 数据处理范围:进货明细账单
- 目标表:进销存明细
- 流程观察:
- 是什么数据作为子流程的节点数据(作为代码块里面批量获取的数据)
- 数据新增到哪张表(作为代码块里面批量新增时的数据)
- 新增的表还需要哪些数据,放到 input 里(例如:其他关联字段、其他静态字段)
1)基础参数处理(需要输入哪些参数)
- 关键入参:
input.id:进货单记录ID(一般为当前工作流触发节点的记录id,用于获取他下面的明细数据)
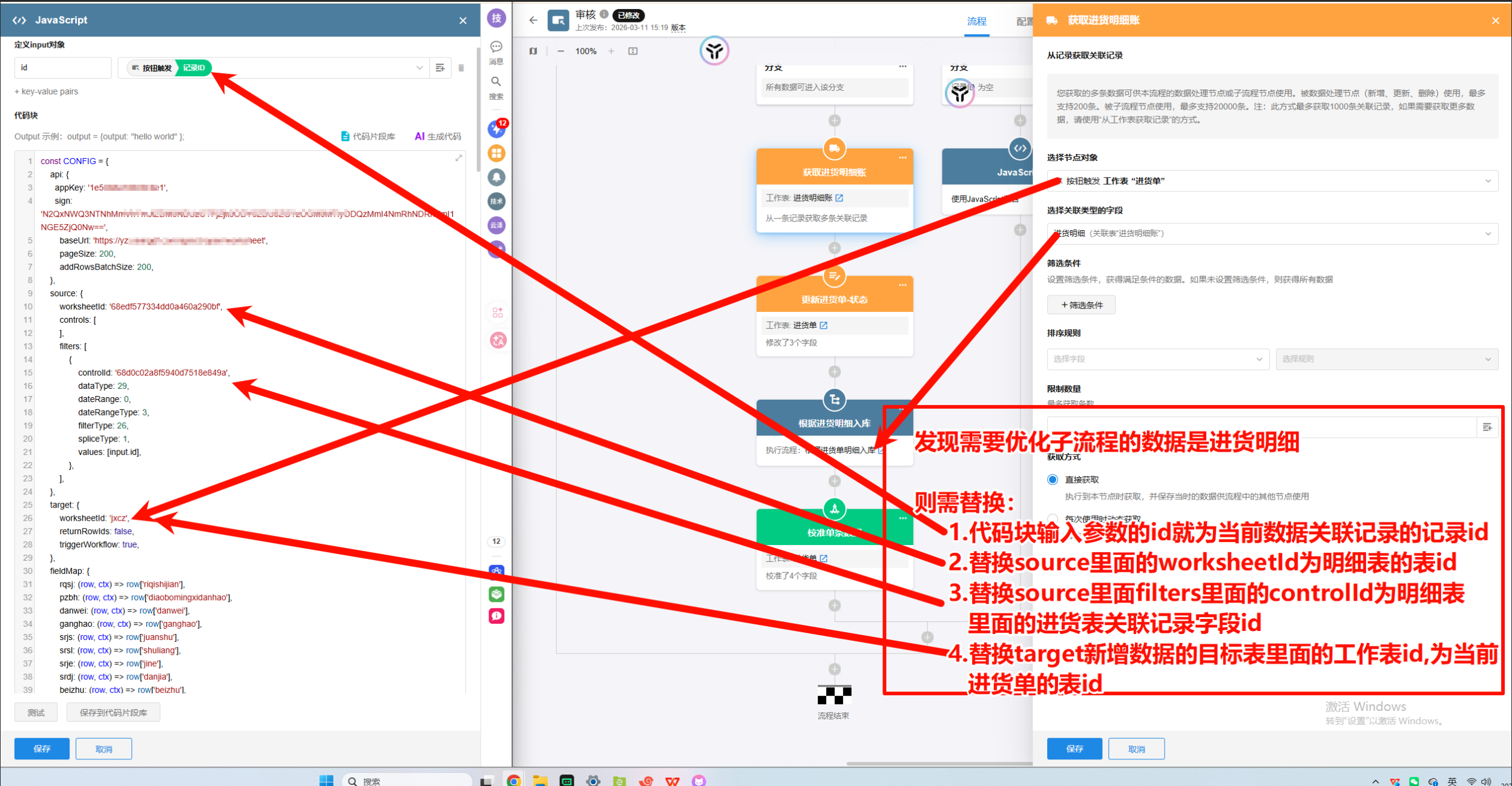
当需要优化的子流程数据是「进货明细」时,需要按下列规则替换:
- 代码块输入参数
id:改为“当前数据关联记录”的记录 id(用于在明细表里筛选出本单据的明细行) CONFIG.source.worksheetId:改为“进货明细表”的工作表 idCONFIG.source.filters[0].controlId:改为“进货明细表里关联进货单记录”的字段 idCONFIG.target.worksheetId:改为“要新增写入的目标表”的工作表 id(例如进销存明细表)
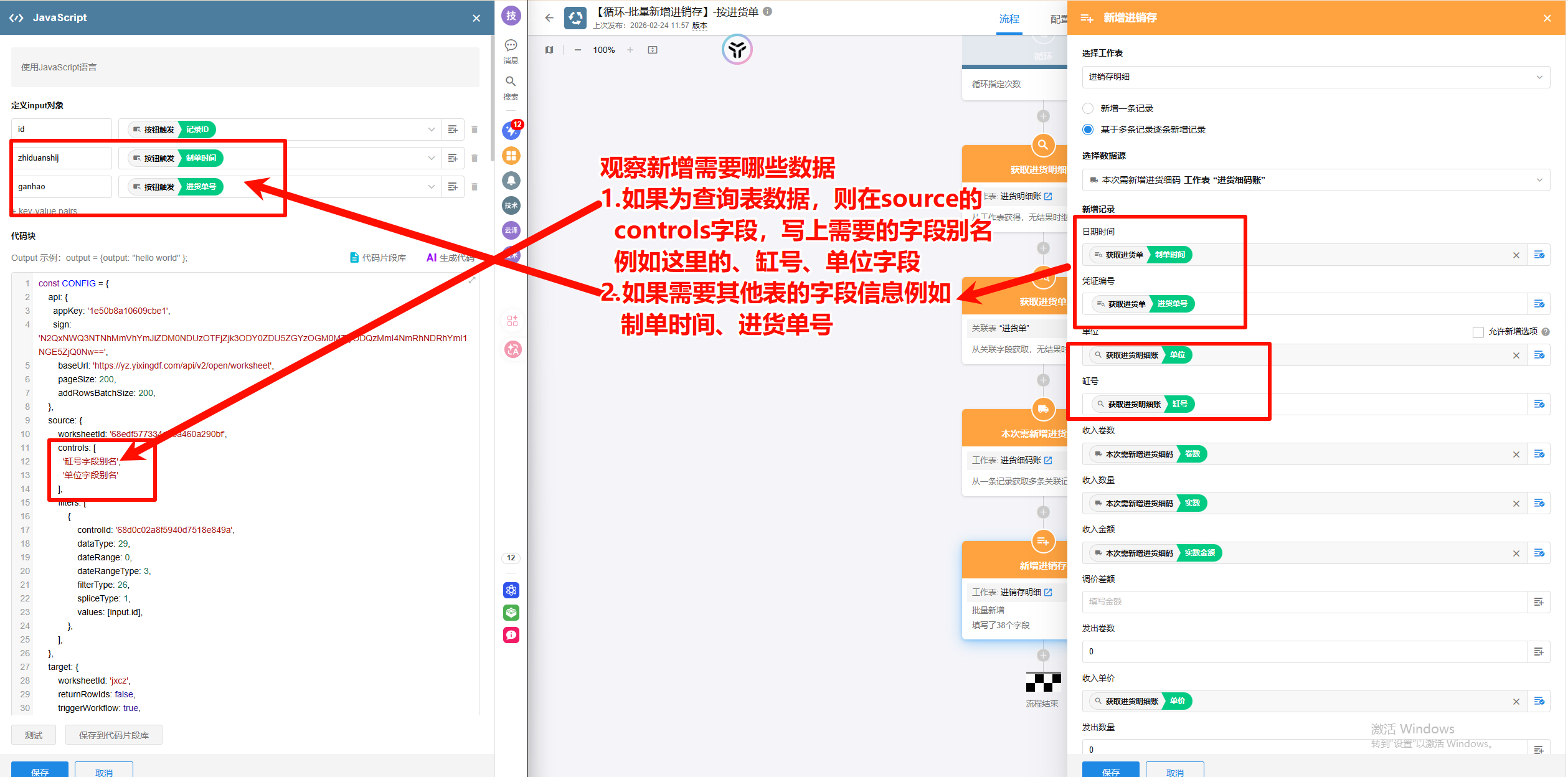
新增前先“观察目标表需要哪些数据”,一般分两类补齐:
- 来源表就能查到的数据
- 写在
CONFIG.source.controls里(只取需要的字段别名) - 例如:缸号、单位等
- 写在
- 需要从其他表/触发节点带进来的数据
- 放到工作流代码块
input里(由触发节点或上游节点传入) - 例如:制单时间、进货单号等
- 放到工作流代码块
- 对应
CONFIG.sourceCONFIG.source.worksheetId:来源表CONFIG.source.controls:只取本次需要字段CONFIG.source.filters:过滤条件(建议以input.id精确限定)
- 截图占位:取数节点配置(这里后补)
3)代码块节点(批量新增核心)
- 代码:直接使用同目录 code.js
- 代码块入参(必填):
input.appKeyinput.sign
- 你需要在代码里改的配置(必改):
CONFIG.source.*、CONFIG.target.*、CONFIG.fieldMap
- 截图占位:代码块入参、代码内容(这里后补)
4)结果回写/通知节点(可选)
- 建议记录:
output.timingMs.total、output.build.rowsCount、output.build.batchesCount - 截图占位:通知/日志/回写(这里后补)
运行结果示例(输出结构)
output 示例(执行后返回)
json
{
"ok": true,
"source": { "worksheetId": "xxx", "count": 123 },
"target": { "worksheetId": "yyy" },
"build": { "rowsCount": 123, "batchSize": 800, "batchesCount": 1 },
"timingMs": { "query": 0, "build": 0, "add": 0, "total": 0 }
}4. 容错与性能建议
- 分批大小:从小到大试(50 → 100 → 200),以“不超时 + 总耗时最低”为准
- 幂等处理:为每条数据生成唯一业务键,避免重试导致重复写入
- 失败重试:只重试失败批次,并输出失败原因与失败数据定位信息
5. 验证与指标
- 记录:总条数、批次数、每批耗时、失败批次
- 对比:优化前/后总耗时与超时率
维护负责人:技术部
最后更新:2026-03-20